My learnings on Linux BPF container performance engineering
Starting with Docker
Over the past few years I’ve worked a lot with container workloads. It all starts with a need to run containers whether its a batch job, a microservice or some scripts. Learning about containers will have you learn about Linux since containerisation is made possible by Linux kernel features, starting with cgroups and namespaces Docker files are Linux file system overlay definitions, volumes are Linux mount points, and entrypoints are Linux commands with arguments. So it’s hard to build containers without learning a few things about Linux.
Since all workloads I work on are running in containers, on Linux, there is always a need to monitor and understand performance of these processes. Whether it be DNS conntrack flooding, CPU saturation, memory leaks, oom kill events or TCP latency.
Performance Engineering
Developers write code which may not be optimal. Dependencies used in code, may not be optimal either. An example would be programming languages that allow developers to misuse HTTP client connections and asynchronous HTTP calls. Some code can unexpectedly cause spike in CPU cycles or memory leaks. Either way, code cannot always be trusted to perform well.
Containers usually run on shared hosts so understanding resource usage and performance is important for not only cost, but also stability.
Metrics and telemetry can be a good way for teams to observe how code or systems are performing. Prometheus monitoring is a great way to expose metrics in Kubernetes and workloads running on the cluster.
Problem I find is that most metrics and telemetry have to be setup up front and only really tell the “known” story. It may indicate CPU is going up, containers are crashing or memory usage is high.
But what about the unknowns ?
Linux Kernel & Observability
The answer is right under our nose. Everything runs on the kernel, everything passes through the kernel. The technology got me absolutely hooked when I studied a performance problem in an application that had a memory leak. The application also had DNS issues. Digging through Linux tools I came across sysstat. I’ve added the tool to my dockerfile repository on GitHub.
I then run it like this:
alias sysstat='docker run -it \--rm \--net host \--pid host \-v /etc/localtime:/etc/localtime:ro \aimvector/sysstat'Running these tools in docker helps me keep production systems free from unnecessary installs. It does have some caveats though. The cgroups and namespaces + mnt points can sometimes isolate tools and what they can see and do. This can also give you a skewed view of the system. You have to ensure you run containers with the correct mount points and understand what these tools need in order to get the full picture of a system.
Tools from the systat stack that helped me identify issues were mpstat , pidstat and sar.
Also, tcpdump helped me identify network bottlenecks too. It wasn’t until I researched about the internals of tcpdump when I discovered a technology called BPF. I started searching the web for BPF talks. What was most fascinating was a talk by Brendan Gregg from Netflix. I can’t recall which talk it was, because every talk by Brendan is great as I started searching for more and more of his conference talks and binge watched most of them.
The origins of BPF came from “Berkeley Packet Filter” technology used in tcpdump to trace network packets. Many Linux tracing tools do work and transfer between user space and kernel space and can sometime add blocks or break points in system calls which can slow the system down. BPF on the other hand enables the kernel to do very efficient tracing by running an intra-kernel virtual machine. How insane is that ? The Kernel has a VM built-in!
So when running a command like tcpdump , the client creates byte code which is sent to the kernel to be executed in the kernel VM in a sandbox. This is safe for production since it’s sand boxed to prevent panics unlike kernel modules. It’s also very efficient since it reduces chit-chat between user and kernel space. Also, all the frequency counting is done within the kernel.
Be sure to check out Brendan’s blog
The IO Visor Project
Brendan’s work lead me to the iovisor project. This community which is part of the Linux foundation build up in-kernel analytics, monitoring and tracing tools. This is right up my alley!
In the iovisor repository on GitHub, I found all the BPF tools I could want. They have a project called BCC which are pre-compiled BPF tools.
You can see some of the tools in the image below:
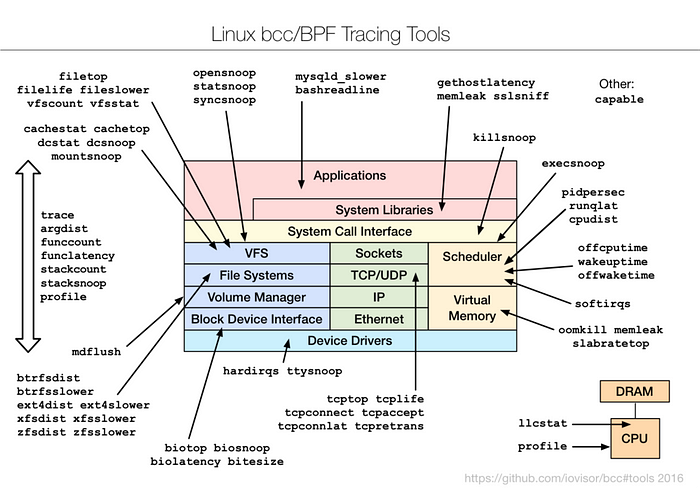
Now that I found the tools I need, I wanted to containerize it so I can run it in pods on Kubernetes!
Since I was interested in tools/profile.py I wanted to profile containers on a docker host. Given I could run a container in --privileged mode then run profile.py on it, I had to make sure my profiler container had the right uname lib modules (linux-headers package).
Building a profiler in Docker
I created a base dockerfile and then I needed a specific one for Azure cloud which is in that repository too
FROM ubuntu:bionic-20191029 It’s important to target Ubuntu here, since my Kubernetes nodes are running Ubuntu. It’s also easy to get the BCC tools installed with a bionic base image. I then install the iovisor dependencies:
RUN apt-get update && \ apt-get install -y curl perl gnupg2 git htop bash lsb-release apt-transport-https ca-certificates
RUN apt-key adv — keyserver keyserver.ubuntu.com — recv-keys 4052245BD4284CDD && \echo “deb https://repo.iovisor.org/apt/$(lsb_release -cs) $(lsb_release -cs) main” | tee /etc/apt/sources.list.d/iovisor.list Then I’m going to need docker CLI so I can inspect containers and hijack their pid information. I also install Linux headers that match the underlying kernel version. Make sure you install the correct one, else BCC tools will complain linux-headers-$(uname -r)
RUN curl -fsSL https://download.docker.com/linux/debian/gpg | apt-key add — && \ echo ‘deb [arch=amd64] https://download.docker.com/linux/debian buster stable’ > /etc/apt/sources.list.d/docker.list
RUN apt-get update && apt-get -y install bcc-tools libbcc-examples linux-headers-$(uname -r) docker-ce-cli And then finally we grab the BCC and Flame graph utils:
RUN mkdir /workWORKDIR /work RUN git clone — depth 1 https://github.com/brendangregg/FlameGraph && \ git clone — depth 1 https://github.com/iovisor/bcc
ENTRYPOINT [“/bin/bash”]If you’re running in the cloud, installing linux-headers might not work and you might need to source the correct packages. Be sure to check uname -r on your target server and search for the right header packages for that kernel. Example of Azure (4.15.0–1063-azure) :
#linux-headers-azure for EBPF in the cloud :)
RUN curl -LO http://security.ubuntu.com/ubuntu/pool/main/l/linux-azure/linux-headers-4.15.0-1063-azure_4.15.0-1063.68_amd64.deb && \ curl -LO http://security.ubuntu.com/ubuntu/pool/main/l/linux-azure/linux-azure-headers-4.15.0-1063_4.15.0-1063.68_all.deb && \ dpkg -i linux-azure-headers-4.15.0-1063_4.15.0-1063.68_all.deb && \ dpkg -i linux-headers-4.15.0-1063-azure_4.15.0-1063.68_amd64.debSo having this image compiled, it would be my profiler for a targeted Kubernetes cluster.
Profiling a host or container
Once the image is built, running it is quite simple:
docker run -it --rm --privileged \ --pid host \ -v ${PWD}:/out \ -v /etc/localtime:/etc/localtime:ro \ --pid host \ -v /sys/kernel/debug:/sys/kernel/debug \ -v /sys/fs/cgroup:/sys/fs/cgroup \ -v /sys/fs/bpf:/sys/fs/bpf \ --net host \ aimvector/flamegraphOnce we launched the container we’ll be attached to a bash shell and can start profiling a process, where $PID is the process ID
./bcc/tools/profile.py -dF 99 -f 15 -p $PID | \ ./FlameGraph/flamegraph.pl > /out/perf.svg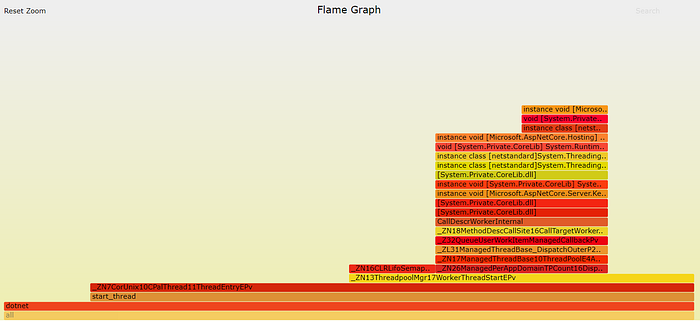
That will spit out a flame graph in our working directory and we can study call stack counts to see where CPU can potentially be busy.
I have created a short guide you can follow here
I’ve had fun making a video about it as well, check it out below
Next up, I will show you how to automate this process using the Kubernetes kubectl utility to target a node or pod, profile it, and automatically get a flame graph back out. This is very useful to quickly profile containers on Kubernetes that eat up CPU and get an understanding of what the workload is doing.
Having a blast with the technology, be sure to follow along over on Youtube
Until next time,
Peace!
